我们整理分类了 halo2 discord 上面的 Q&A,大部分学习中遇到的问题都可以尝试先在此进行分类搜索
- Basics
- Curves
- materials
- gadgets
- waiting fix:
- serialization/deserialization
- wait to be organized
- folding/recursion
- wait to be organized…
- Others
Basics
Q: What’s the actual difference between assign_advice_from_constant and assign_advice in practice?
A: @ying tong
assign_advice_from_constant:
- (at keygen) assigns a constant value to a cell in a fixed column;
- (at keygen) sets up an equality constraint between the fixed cell and the advice cell;
- (at proof gen) assigns that same value to the advice cell.
assign_advice only does step 3).
Q: what’s the difference between PSE Halo2 and original Zcash Halo2?
on a high level: the PSE fork of halo2 supports more features; however, it is worth noting that the zcash/halo2 implementation has been audited. many of the useful features in PSE are pending upstreaming under the nightly flag. here is an incomplete list of the notable differences:
- commitment schemes:
zcash/halo2only supports IPA, while PSE additionally supports KZG - lookups:
zcash/halo2only supports fixed tables, while PSE additionally supports dynamic tables - challenge API: PSE supports multiple rounds of commitments and challenges
I think PSE switches use of inner product argument for kzg commitment?
is there an end-to-end example of halo2 proof & onchain verification in Solidity?
- https://github.com/privacy-scaling-explorations/snark-verifier/blob/main/snark-verifier/examples/evm-verifier.rs
comparison I am a beginner in Halo2, and I want to create a proof using Halo2 to check whether the user’s age (userAge) is greater than or equal to the target age (targetAge). Does Halo2 support comparison operators? If yes, then how can I define the comparison gate and write the comparison function?
SUNYI:
- https://axiom-crypto.github.io/halo2-lib/halo2_base/gates/range/trait.RangeInstructions.html#tymethod.is_less_than
- This uses halo2-lib: https://github.com/axiom-crypto/halo2-lib
Could this algorithm be implemented somehow in halo2/plonk? :
#![allow(unused)] fn main() { def f(a, b): if a == 0: return a else: return b }
i think you could witness is_zero_a = isZero(a), and use it to constrain the output :
is_zero_a * (output - a) + (1 - is_zero_a) * (output - b)
Daira:
how is isZero implemented? to constrain is_zero_a correctly for both cases, you would need to witness alpha = inv0(a) and then constrain is_zero_a * a = 0 and (1 - is_zero_a) * (1 - alpha * a) = 0, as well as boolean-constraining is_zero_a
but that may be what isZero does;
I’m not sure. I couldn’t find it in halo2_gadgets
(IIRC there’s a way to do it in one fewer constraint, but I forget what that was.)
yup, i’ve seen an IsZero like that: https://github.com/privacy-scaling-explorations/zkevm-circuits/blob/6bcb1d052a75886f4a2379347b84fa2bd1ff2bea/zkevm-circuits/src/evm_circuit/util/math_gadget/is_zero.rs
Q: Hey gust! What happens if we reference the previous row in a gate that is active at the 0th row? A: this will “wrap around” to the last row. in halo2, the last few rows of the advice columns are set to random values: https://github.com/zcash/halo2/blob/f9838c127ec9c14f6f323e0cfdc0c1392594d37f/halo2_proofs/src/plonk/prover.rs#L293-L298 i wrote up a minimal example for this (constraint will fail, since the last row has a nonzero random value): https://discord.com/channels/995022112811135148/1154777246188445736/1154843452236910715
Q: Hi, want to make sure, if we dont assign any value to a cell, is it default to 0? Thx! YT: yes, unassigned cells are initialised to 0 in the current implementation; but this is an arbitrary implementation choice, and we shouldn’t rely on it being true. e.g. there was some discussion about randomising unassigned cells: https://github.com/zcash/halo2/issues/614
Q do we need to learn complete rust to build zk-protocol using halo2? A Yes, actually there’s no DSL for Halo2. So the only way to write circuits for it (That I’m aware of) is using the Rust API that the library provides.
I’d not say that you need to be proficient in Rust to write circuits but definitely need to be familiar with the basics of the language.
1. What is the difference between public input and the constant?
A: public input can change between different invocations of the prover, whereas a constant is fixed across all proofs.
- In every example I found so far we need to define the add, mul, load_private/constant, expose_public. If those are so popular I suspect they were implemented in some standard library and can be reused?
A: This is what the halo2_gadgets crate is for! It provides a bunch of common gadgets (and chips for them) that can be reused.
- If the above is true, does that mean that SimpleExample can be done without implementing a new chip but rather just reusing some other existing code? To me, it seems as if I was trying to learn C++ and someone gave me a hello world that contains operator overloading:)
A: Indeed, it could be. SimpleExample is really providing an example of two things: how to build a circuit, and how to build a custom gadget and chip. It would be useful to split it into two separate examples in the book! I’ve opened an issue for this: https://github.com/zcash/halo2/issues/727
Note however that https://github.com/zcash/halo2/blob/main/halo2_proofs/examples/simple-example.rs cannot be refactored in this way, because it is an example of using halo2_proofs directly; we don’t have access to halo2_gadgets there.
- In the circuit, we need to overwrite the configure method. The first argument to that method is the
metaargument. What is this argument? It seems like a lot of useful methods are located in this object but I am not sure what is the idea behind and when and where should I use it. As I understand I can access instances of layouter to add new regions for example. But what is the main use case for meta?
A: meta has type ConstraintSystem, and is used inside Circuit::configure to configure the circuit. This is where you tell the backend how many columns (and of what kinds) you are going to use in your circuit, what gates you want loaded, etc.
Chips generally provide a SomeChip::configure method that implements this logic for their needs, which you call inside Circuit::configure if you want to use that chip in your circuit.
- I am a little confused between the circuit and execution trace. When we use a plotter to generate colorful images, it seems to me what it represents is an execution trace that the circuit can apply it’s gates to and verify. Could you please clarify what it actually shows so I have the base foundation straight?
A: This is not showing an execution trace, but the actual “physical” layout of your assigned cells in the circuit. The red columns are advice columns; blue columns are fixed columns; and white columns are instance columns / public inputs. Green boxes represent calls to layouter.assign_region, and it’s inside those that the actual cell values are assigned.
- I am trying to understand how the chip integrates into the circuit. So in the configure function of the Circuit, we declare all the columns we might need. Then we call the configure function of all the chips that we want to use. Those chips in their configure methods call any configure methods of chips they use. What I notice in the two-chip.rs example is that we only need to define the columns once and then pass them to the appropriate chips. Does that mean that all chips will be reusing the columns defined in the Circuit? Or due to some rust variable borrowing magic, only the chip who’s configure we called last will have access to the columns.
A: Yes, columns can be reused by different chips. As the circuit designer, you get to choose how you “connect up” the chips you are using. You could have all chips use the same few columns, or you could define a bunch of different columns so each chip gets its own set.
- I am missing some understanding on how the gates are applied to the execution trace or circuit(not sure of the correct term here). Does every gate gets applied to every row, on columns that are passed into the gate in the column argument? Would be cool to see a visual that would show the values that were loaded in to the regions, on top of the colors, and see how the gates are applied. Does such a tool already exist?
A: Every gate is applied to every row. Think of gates as like Tetris pieces that you hold over every row, and each cell covered by the Tetris piece is used by the gate on that row. This is why we have “selectors” that you can use to enable the effects of a gate only on specific rows.
Re: tooling, this is something I’ve wanted for a long time, but I lack the JavaScript skills to implement it myself.
- the difference between copy_advice and assign_advice_from_instance . From the source code I can see that the copy one also adds a constraint that advice must be equal to the instance column, but from Haichen’s talk at 0xPolygon I can see that assign one does that as well. What would be the difference? Also please let me know if I should use the previous threads for additional questions. Thank you! A: The difference is tha copy_advice adds a copy_constraint between two columns at a particular offset also setting the value from one to the other. This, not only assings a witness but also forces the permutation argument to include a copy constraint. The particular difference from assign_advice_from_instance is that copy_advice copies Advice columns while the other copies from Instance columns(so public inputs) into Advice columns.
So in summary:
- assign_advice_from_instance -> Copy From Instance -> Advice.
- copy_advice -> Copy from Advice -> Advice
Yep. The reason that assign_advice_from_instance exists is that the instance column needs its ordering to be known to the circuit user (so that the verifier can provide the public inputs at the correct locations), and if an instance column gets used in a region it interferes with the floor planner being able to reorder regions for efficiency. So we instead have you copy the public input value from its known instance column location into an advice cell inside a region, and then use it from there.
Q according to you is halo2 better than circom and why? A I think there’s no better or worse. They serve the same purpose but apply different techniques.
While in halo2 you have the power and expressiveness of Rust to help you, you also pay the prize with more verbosity.
Instead with Circom, you don’t have that expressiveness and instead you have concise instructions which are purely the circuit and not rust-only stuff.
Depends on the taste and person. I can’t say that something is categorically better or worse.
Curves
Q: Regarding the generation of Pallas/Vesta or Pluto/Eris, is there some reasons why the parameter b should be the same for both curves in the cycle?
A: Just convenience of implementation It doesn’t constrain the search significantly; you can always find such a b that is the same for both curves. What does constrain it is picking b in advance, which we also did for simplicity.
Q: Is the cell value of Halo2 arithmatization an element of base field or scalar field of the Pallas curve ? Given the cell is the evaluation of polynomial on the root of unity, is it supposed to be an element of the scalar field?
A: currently, proofs from zcash/halo2 are computed on the Vesta curve; so the circuit values are Vesta scalars (i.e. Pallas base field elements).
Q: Ah I see, thanks for explaining, but the ECC gadget is computed on Pallas curve?
A: yes, since it’s working with curve points whose coordinates are in the Pallas base field; in other words, Pallas curve points.
Q: Hello trying out the KZG fork, can I use pasta::Fp in ParamsKZG? Or should I abandon pallas?
A: Pallas and Vesta are not pairing-friendly, so they can’t be used directly with KZG
Hey all.
I’d like to know why https://github.com/zcash/halo2/blob/76b3f892a9d598923bbb5a747701fff44ae4c0ea/halo2_gadgets/src/ecc/chip.rs#L140 is forced to use pallas::Base ,when if made generics, this could serve as a chip for any elliptic curve with the same properties.
I’ve seen https://github.com/zcash/halo2/blob/main/halo2_gadgets/src/ecc.rs#LL40C1-L43C59 but I doubt that this is a blocker actually. You can have a trait that actually has these constants as functions instead and they return a constant result always.
I’d appreciate if you could explain if there’s any other limitation aside from the second link I sent. As on that way, I might give a shot to the actual task of removing the generics.
Daira: I think I never actually confirmed the assertion that p and q can be swapped safely in that implementation, or what exactly it depends on. The security analysis was done only for Pallas.
For the Orchard circuit, the proof system is over Vesta and the curve multiplication is over Pallas. The scalar is given as a Pallas base field element, which is smaller than Pallas’ scalar field. If it were the other way around, the scalar could overflow, and the consequences of that are what haven’t been analysed.
Thanks @Daira Emma (ze/hir) — ECC ! My question wasn’t targeting Vesta specifically. Rather, targeting the possible implementation of Pluto-Eris with the ECC chip. Or in general, allow any Weierstrass curve to use this chip.
Hence, on that line of thought I was asking if it would be a big issue to just try to remove the issue introduced by FixedPoints so that we can have a trait instead of a fixed type (pallas::Base ) in this case. or, instead, there are still hidden issues if we try to impl other curves.
Also, is it possible that by removing some optimizations, we can make the ECCChip able to swap curves? Or is it that by design, one chip serves for only one curve?
There are still hidden issues, but it can be generalised with a bit of work (and that’s on our roadmap since it’s needed for recursion)
As you say, some optimizations would need to be removed, because the current implementation depends on the fact that p and q have bit pattern "1 <many zeroes> ..."
the short answer is that we originally made it generic, but didn’t have the engineering bandwidth at the time to ensure that the implementation was actually safe generically, so we specialised it to reduce reviewer burden.
materials
Q: Hi there, I am exploring Halo2 project and have checked out the Halo2 book and lectures offered by 0xParc. But I still can’t find a formal documentation like rustdoc for the helo2 core library even for early edition. Is there anything like that, or how can I have a more complete view on the functionalities that core components provide? (Like Chip, Config, Circuit, MockProver, Layouter etcs). Any informal material can be a great help!
A: There are links to doc on crates.io pages
https://crates.io/crates/halo2_proofs https://docs.rs/halo2_proofs/0.2.0/halo2_proofs/
https://crates.io/crates/halo2_gadgets https://docs.rs/halo2_gadgets/0.2.0/halo2_gadgets/
And I guess cargo doc –open being run on source code will give you docs on exact commits if you need other version than 0.2.0
recursion material to halo2_proofs
Q: is recursion material to halo2_proofs? or is plonkish arithmetization > ipa something that happens without any recursion?
A: The latter. Halo 2’s recursion capabilities (once implemented) will be built on top. The Halo 2 protocol is designed with awareness of, and intention to support, recursion. But that just affects how the base protocol works; it doesn’t necessitate recursion in order to use it.
Q: good to know - doing a writeup on battleships and wanted to make sure I frame things right
A : Halo 2 as a protocol is effectively a synthesis of Plonkish arithmetization, and a polynomial commitment scheme that is amenable to the Halo recursion technique. (And also a bunch of other things that make the overall proving system more efficient, and API designs for making it possible to build fast and safe circuits, etc.)
gadgets
Poseidon
we’re struggling to hash a variable-length input using the default Poseidon implementation from halo2. since the library only implements the ConstantLength Domain, I assume that we need a different implementation for the VariableLength. Could anyone point us to a project that’s doing that, or guide us on how to implement that?
YT: it looks like the axiom fork does variable-length Poseidon (https://github.com/axiom-crypto/halo2/tree/main/primitives/poseidon):
idk how this interacts with Poseidon standardisation efforts, @str4d - ECC might have a better idea: https://github.com/C2SP/C2SP/pull/3
there isn’t a restriction on L to be a multiple of RATE, because we pad the input to a multiple of RATE: https://github.com/zcash/halo2/blob/main/halo2_gadgets/src/poseidon/primitives.rs#L319-L327. however, there is a bug in the loading of the padding words, which should be fixed by this PR: https://github.com/zcash/halo2/pull/646 (i’m going to bump this PR for re-review, i don’t recall why we didn’t merge it the last time)
Q: Hi team, I wonder whether there is any reference/example on how to use Poseidon gadget of Halo2? I’m rather in engineer background and don’t know the very detail of Poseidon hash function. I just find it extremely painful to use this gadget https://docs.rs/halo2_gadgets/latest/halo2_gadgets/poseidon/struct.Pow5Chip.html
Some specific questions are: (1) What are the meaning of WIDTH/RATE parameter and how I should choose them? (2) What are the usage of state/rc_a/rc_b/partial_sbox column and can I reuse them for other parts of my circuits? (3) How can I assign cells for the Pow5Chip (through Hash::hash?)? (4) Which library is recommended to calculate the ground truth for hash result, as they all have different setups (field, parameter….)? (e.g. https://github.com/ingonyama-zk/poseidon-hash)
While I’ve used Poseidon in Circom which is just one line work like “component message = Poseidon(2)”
A by himself: For the above question, I just find it a great illustration in test cases of the library ! 😀
padding
Hello, everyone.
If I want to implement the padding in zkp circuit using halo2, how can I do that?
For example, I would like to implement the padding of md4 hash function. It includes padding the extra bytes to the end of original message.(Assuming that message is byte array - Vec<u8>)
(Seems silly question, but would like to know how to do it if possible)
I think SHA256, Poseidon, and Sinsemilla might be good reference implementations. (https://github.com/zcash/halo2/search?q=padding). https://github.com/zcash/halo2/blob/a19ce33c395eb14f951e4d64d1bd3c7d6f714366/halo2_gadgets/src/sha256.rs#L137-L140 looks like the entrypoint for padding in the sha256 gadget
keccak256
Q: hey, is there any demo about how to expose the keccak256 hash result as instances in the halo2 circuit using the BN256 curves? the keccak256 hash result can be convert to be an Uint256 type data, but the BN256 data is about less than Uint254 A: the zkevm-circuits impl witnesses the Keccak output hash as 32 bytes (each of them range-constrained): https://github.com/privacy-scaling-explorations/zkevm-circuits/blob/main/zkevm-circuits/src/keccak_circuit.rs#L524-L531
XOR
Q: I’m just writing a simple XOR chip for understanding lookup table API, have few q:
- Is it okay for witness to contain plain u64 types (not field)? (https://github.com/zemse/halo2-playground/blob/main/src/chips/xor.rs#L129-L130)
- Usually output from chips is an AssignedCell (e.g. mul chip https://github.com/zemse/halo2-playground/blob/f7d58ed14caf114a7d3562ff68c6aa3ccf017e0c/examples/simple_example.rs#L265). Is it possible to calculate XOR by converting the AssignedCell into u64? (to do this: https://github.com/zemse/halo2-playground/blob/f7d58ed14caf114a7d3562ff68c6aa3ccf017e0c/src/chips/xor.rs#L92)
- Instead of
calculate_xor, would it make more sense to pass the result of XOR operation in the witness and then check if it is correct (and use result cell further wherever necessary)?
I see the lookup tables section in the docs is marked TODO so would it be fine if I try to make a PR with the XOR chip as an example? https://zcash.github.io/halo2/user/lookup-tables.html
A:
plain u64 types :Yes, but you will need to implement range constraints somewhere to ensure they are only 64 bits. I see that you separately have a BITS const generic, so really that is what you want to range constrain to (and then somewhere else you should constrain that BITS <= 64).
Is it possible to calculate XOR by converting the AssignedCell into u64?
The way you need to do this is to take the AssignedCell s where left and right have been assigned (most likely by taking them as gadget inputs and then copying them into cells inside the local region), and use .value() to get the Value s assigned into left and right. Then you can compute the XOR as:
#![allow(unused)] fn main() { let result_val = left.zip(right).map(|(left, right)| left ^ right); }
and assign that into the result cell.
zk-ecdsa in halo2?
Axiom has an implementation of that available https://github.com/axiom-crypto/halo2-lib/blob/main/halo2-ecc/src/secp256k1/tests/ecdsa.rs
MiMC
https://github.com/avras/mimc-halo2
waiting fix:
Happy Monday everyone! I am visualizing the circuit and tried filling the circuit for proving that I know x that satisfies x^3+x+5=35. 3 is private input, 5 is a constant and 35 is the public input. I had a few questions where things did not really align for me:
- What is the very first row that is not labeled? I get it in every circuit I visualize.
- Why loading constants takes two columns? All I do is I assign_advice_from_constant.
- To use the constant cell or instance cell in the computations I first need to load it into advice columns? Essentially I am wondering if the load_constant step can be skipped?
- Nothing in the instance column (first white column) is greyed out. Does that mean I have loaded 35 as public input incorrectly?
- Selectors get enabled for the entire height of the region? Trying to understand why mul and add have height of 2 rows and not just one row in the selector columns. Looking at the number table I filled that should not work and 1 should only be set for one row in the region.
Just in case here is the code for the circuit:https://github.com/0xTaiga/SimpleCircuit/blob/main/src/main.rs
serialization/deserialization
Hi everyone! I am working on a serialization/deserialization method to write and read Halo2 circuits and proofs. For instance, when I need to reed and write circuit parameters I can use read and write functions in the impl of the Params public structure and it works well.
My issues start when I try to move forward to the proving and verification keys. I have tried to implement bincode::Encode on a struct that mirrors the ProvingKey struct, but I struggle with the fields of ProvingKey being private. I also came across other things being private that prevent me to write a bincode::Encode implementation outside the halo2 crate, for instance the Module permutation. Are you people aware of a better way to serialize and deserialize Proving and Verifying keys, or I have no choice but to fork the halo2 repo? I would rather not do that. Thanks a lot in advance
Define a stable serialization format for halo2::plonk::ProvingKey https://github.com/zcash/halo2/issues/443
A: Because Halo 2 doesn’t have a trusted setup (and the generators are computed by deterministically hashing to the curve), the only thing necessary to reproduce the proving key is the code of the circuit. Since that’s necessary for proving anyway, I don’t think there’s an advantage to reading and writing proving keys from/to disk. The same argument would not apply to verification: you can verify a proof with just the verifying key, without needing the code for the circuit.
In proving systems like Groth16, it was necessary to read the proving key from disk because there was information stored within it that we couldn’t derive on-the-fly. For Halo 2, reading the proving key from disk would solely be a potential performance optimisation, if it takes less time to read the proving key from disk than to re-compute it.
I recently added key generation benchmarks to benches/plonk.rs, and for its particular circuit structure, I see the following times on a Ryzen 9 5950X:
Q: Hey! I was wondering, what is the intended way of (de)serializing the verifying key struct? If I understand correctly, assuming the verifier is different from the prover, the prover would need to pass the vk along with the proof, presumably over the network?
A:
this is still WIP on zcash/halo2 right now: https://github.com/zcash/halo2/issues/643 but there’s a PR for it that is already being used in some other forks: https://github.com/zcash/halo2/pull/661
wait to be organized
arithmetisation
Q: Can a row be described as a step of computation in the sense a computation is flatten into many steps(rows) and cells are the computation trace? without using the math description behind it, i.e. nth root of unity
YT: i think this is the model used by AIR arithmetisation, where a single relation is uniformly checked on each row.
the PlonK arithmetisation allows us to express less uniform relations, e.g. it could be that a relation only applies on some rows; or is irregularly “shaped” and only applies to part of a row; or spans multiple rows; etc.
A: You are right, thanks for pointing out, so each step of computation can be represented by any shape (region) in the Plonkish matrix? There is no significant meaning of a single row except it is nth root of unity?
str4d - ECC: Indeed. It’s easier to think of the rows and columns as “area” that can be filled by the initial, intermediate, and final values within the computation, similar to laying out a circuit board or computer chip.
So e.g. you could have “steps go sideways” by having your constraints mainly reference cells in a single column, but have the overlapping references go into adjacent columns. It would definitely be unusual (because the root of unity logic means the constraint applies to all rows, not all columns, so you don’t get automatic tesselation), but it might make sense for some kinds of circuits (e.g. I could imagine representing some kind of layered neural network structure where you want to apply the same constraint to a bunch of adjacent cells that feed into overlapping “outputs” in the next layer, that you could maybe represent in this way).
More usually, you define some small regions in which you have a small sequence of computation (so inside that region, you could likely consider each row of the region to be a “step”), but those regions can be positioned arbitrarily within the overall circuit area (so the “circuit rows” don’t correspond to overall computational steps, unlike AIR).
lookup table、lookup system/SHA256
Since using lookup we can ensure if a tuple of witness values exist in a lookup table. however is it possible to constrain that a tuple of witness values do not appear at all in the lookup table?
Q: Is anyone working on more efficient lookup arguments in Halo2, like Caulk+ or cq? Decoupling proving time from the table sizes would be 🔥
YT: a colleague and i have been working on:
- MVLookup (PSE fork): https://github.com/geometryresearch/halo2/pull/1
cq(Axiom fork) https://github.com/geometryresearch/halo2-cq/pull/1 still very WIP, but it seems promising from initial benchmarks!
dynamic table:
- https://github.com/zcash/halo2/pull/715
- WIP ?
Q: Are there any instructions on creating a dynamic lookup table for prover-time variables?
A:
if you are on the PSE fork, there is the lookup_any API: https://github.com/privacy-scaling-explorations/halo2/blob/main/halo2_proofs/src/plonk/circuit.rs#L1725-L1749
Q: Hello, halo2-ers, I’m a newbie in the Halo2 zkp system, I have been confused about the lookup system, when we construct the lookup for the zk unfriendly operations like sha256/keccak256, how do we confirm the validity of the ops lookup table that have built?
A lookup argument simply checks that a value is inside of a table. Indeed, the real lookup argument checks that one set of arguments is a subset or a permutation of another one.
So for instance, you might want to:
- Have a circuit/gate that executes the Hash (provided a set of inputs) and returns the output.
- Make this circuit expose this relation Input - Output in a lookup table.
Then all users can lookup this table with input-output with the guarantee that each relation has been constrained already. So to make it easy, you just need to compute the hash once, and then you can look it-up N times 🙂 The issue normally is that the inputs of the hash do not fit inside of a column and then you need sophisticated designs to sort this out.
You can also use Chips like the SHA256 in halo2_gadgets for example which are already build and just require to put the things inside tables.
Q:
Hello, I would like to ask question about lookup & table column. Why the table column cannot be re-used as ordinary fixed column? I found that the table column is, in essence, fixed column, wrapped inside TableColumn struct. Also, I would like to know the detail of permutation used in lookup argument.(I read that it is different from that of plonk).
A:
currently, halo2 fills in TableColumns with a specified default value, which is why we cannot used an ordinary Fixed column as a TableColumn. but i actually don’t see what’s stopping us from using a TableColumn as an ordinary Fixed column.
it is true that both the permutation and lookup arguments internally make use of some variant of multiset equality.
however, the permutation argument does so on tagged cells, thus enforcing a specific permutation.
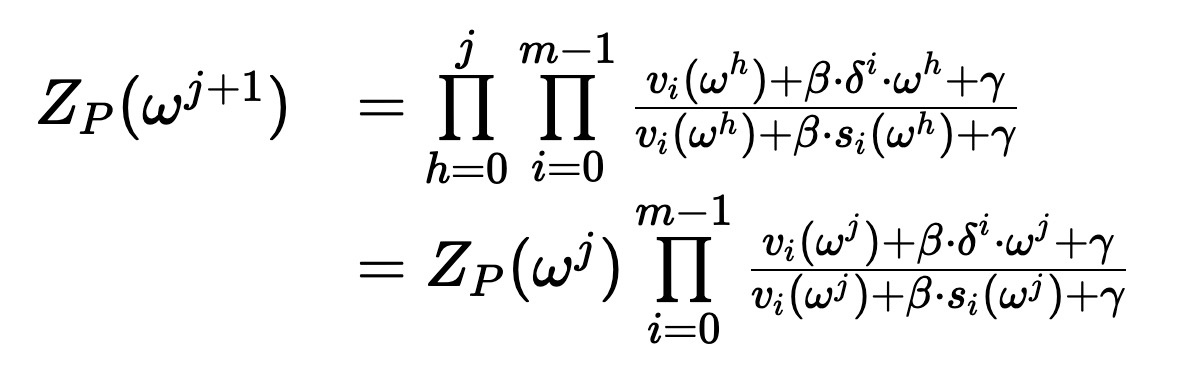
whereas the lookup argument does so on untagged cells, thus allowing any permutation.
 (note that the complete lookup argument involves additional checks besides this multiset equality check.)
(note that the complete lookup argument involves additional checks besides this multiset equality check.)
str4d:
The problem is that whatever goes into a TableColumn needs to be valid for the table lookup, because technically the entire column is in the table due to how the lookup argument is constructed, regardless of how many rows the real table has.
Dynamic lookup tables fix this with the tag column, which restricts the range of rows over which a lookup will constrain a table, thus freeing up the rest of the column’s rows for other things.
So you pay the cost of one or more separate fixed columns for the tags, but in exchange get to split up the table columns by row.
Some more questions:
- Currently, the dynamic lookup table idea is implemented in halo2?
- If so, can you give me reference or example code?
- In case of dynamic lookup table, it looks like I can re-use other rows of table column as one of ordinary fixed column. right?
The implementation is in https://github.com/zcash/halo2/pull/715, which we are working to get merged as a nightly (and therefore unstable) feature (https://zcash.github.io/halo2/dev/features.html).
Selector optimism
Q: Is the layouter automatically optimizing for selectors? From the printing of the circuit, it seems that the number of selectors added to the circuit is equal to the max number of selectors that are enabled at the same time. For example, if the circuit config contains 10 different selectors, but at max 2 of them are enabled together in a region, the circuit wll only have 2 selectors. Is that correct? A: yes, the layouter combines mutually exclusive selectors into fewer fixed columns. however, it only does so up to the maximum degree bound. there’s a write-up of this optimisation at https://zcash.github.io/halo2/design/implementation/selector-combining.html
copy instance col
Q: Hi all, quick question. how would one copy a variable length instance into an advice column? My tmp solution is to keep calling assign_advice_from_instance until I get an Err, but is this the idiomatic way?
A: An instance value cannot truly be variable length: you eventually run out of circuit rows to fit it in. Generally in this kind of case, what you need to do is have a hard-coded maximum length, and always copy that in, and then have logic inside the circuit to handle the variable length.
Note however that the circuit needs to always perform logic on the full maximum length of the instance value (circuits always encode “worst-case performance”), so you need some way of performing “dummy” operations on the instance value.
Alternatively, if you don’t mind different-length instance values using different circuits (which from a privacy perspective is fine because the instance values are by definition known to the verifier), then add a const generic length parameter to your circuit. Then within that circuit you can treat the instance value as a fixed length.
Ah I see! Thanks for such a detailed explanation.
cost
- cost model for IPA: https://github.com/zcash/halo2/blob/main/halo2_proofs/src/dev/cost.rs
this cost.rs file looks potentially quite useful: https://github.com/zcash/halo2/blob/main/halo2_proofs/src/dev/cost.rs but there’s no documentation i can find; how do i use this with my circuit? is it built in somehow? or do i manually fill all of the values?
You call CircuitCost::measure(K, your_circuit) where your_circuit is an instance of your struct that implements Circuit
cool, this worked:
#![allow(unused)] fn main() { println!( "{:?}", CircuitCost::<Eq, MyCircuit<Fp>>::measure( (k as u128).try_into().unwrap(), &circuit ) ); }
there was a smol bug with lacking permutation checks that I’ve posted about here: https://github.com/zcash/halo2/issues/748
Q: why rotation is costly in halo2?
A: I wouldn’t say it’s excessively costly. But use of rotations does increase the number of commitments in the proof (see https://github.com/zcash/halo2/blob/main/halo2_proofs/src/dev/cost.rs for the details)
folding/recursion
Has anybody implemented the Folding scheme for Halo2 lookups? I am curious how efficient it’s going to be. Thanks. @yisun https://hackmd.io/@aardvark/rkHqa3NZ2
There is an implementation of Sangria here which I believe also incorporates some form of lookups: https://github.com/han0110/plonkish/tree/feature/sangria
Q: Maybe this should be asked in recursion channel, but anyway I’m asking here. I didn’t read full paper so please tell me a chapter if it’s written in full paper. I watched video materials and some online resources about recursive nature of plonk circuit. I understand that halo2 works if you can put verification circuit of plonk inside its own circuit, but I’m not exactly sure how this can be achieved. If you first prepare a circuit which is target of verification, then wouldn’t that change the verification logic itself? Are there any proof-of-concept implementation for this chicken-and-egg circuit recursion problem?
A: one solution i’ve seen is for the recursive verifier to take in a verifying key as input, along with the prior proof. this is how it’s done in arkworks-rs/pcd:
- recursive verifier that takes a help_vk as input: https://github.com/arkworks-rs/pcd/blob/master/src/ec_cycle_pcd/data_structures.rs#L85-L100
- where help_vk is used to verify prior proofs: https://github.com/arkworks-rs/pcd/blob/master/src/ec_cycle_pcd/data_structures.rs#L296-L301
- chain of recursive proofs in a test: https://github.com/arkworks-rs/pcd/blob/master/tests/mnt4_marlin.rs#L142-L165
in an accumulation scheme, the accumulation verifier does not fully check the prior proofs, but rather checks that they have been combined correctly into the accumulator. e.g. in Nova:
- we fold two previous instances into a new one (https://github.com/microsoft/Nova/blob/main/src/circuit.rs#L285-L297)
- recursive minroot example (https://github.com/microsoft/Nova/blob/main/examples/minroot.rs#L223-L241)
I’m new to Halo2 and the reason I’m learning it is to use recursive proof/verification. However, I see it’s still marked as “coming soon” on the website. Is there any estimates of when it will be available? Is there a beta version that we can start learning and experimenting now? Thank you in advance,
No response
Mockprover
I’m trying to understand what does mock prover do internally? does MockProver::run run keygen-and-prove operation on the given circuit as the comment of the function claims? I couldn’t find where is the keygen called inside the run function
YT:
keygen_pk() collects fixed information about the circuit structure and encodes it in the ProvingKey. this is done using just the constraint system, without an actual witness. at proving time, the prover inputs this ProvingKey and their witness to create_proof(). MockProver::run() combines the two steps by collecting information about the circuit structure + assigning the witness to this structure “in the clear”. this lets us sanity-check an assignment without doing the expensive FFTs and commitments involved in the real proving/verifying process.
I see thank you for the clarification, I thought it would call keygen_pk() explicitly but I realized it’s not necessary as you explained
keys generation
Q Is it possible to compile the halo2 binary and during runtime have it generate a circuit/proving/verification keys? (the circuit is not known at compile time) Something similar to what is possible with circom/snarkjs, where we feed a high-level circuit description to the circom binary, it generates the .r1cs file and we feed the .r1cs to snarkjs for proof/verification.
A @dan not at present, but it’s something we do want to enable in the near term. https://github.com/zcash/halo2/issues/550 is the issue tracking this.
Hi I am trying to build prover and verifier as separate rust binaries and currently facing a problem with keys generation. What is the recommended way of passing proving and verifying keys to separate binaries? I was thinking of generating them in build.rs and serializing to text files to deserialize them later while building binaries, but the structs don’t seem to support serialization out of the box
A: There is currently no way to serialize proving or verifying keys, due to limitations in how the internal types are structured. The tracking issues for this are https://github.com/zcash/halo2/issues/443 and https://github.com/zcash/halo2/issues/449.
What is the reason for create_proof and verify_proof to use params as an argument? As far as I understand, a constructed params instance is a toxic waste as it exposes a random generator used for vk and pk creation and therefore shouldn’t be shared publicly. But if I want to run prover and verifier independently (on different machines, for example) I am supposed to share a constructed params instance therefore compromising random generators used for keys generation. Which gives a malicious party the ability to reconstruct the keys and create malicious prover/verifier. Is there something I am missing on this?
str4d: params is not toxic waste. It is deterministically generated and can be reproduced by anyone who knows the circuit structure (which the verifiers need to know). params is just common data that both the prover and the verifier need. It could equivalently be considered “part of the verifying key”.
YT: the params contain only public information:
- zcash/halo2 does not use a trusted setup. Params contains a vector of random curve points g:
Vec<C>, which are not secret values. rather, they are generated in a transparent way using public information: https://github.com/zcash/halo2/blob/main/halo2_proofs/src/poly/commitment.rs#L47-L62 - there is a fork of halo2 that replaces the IPA commitment scheme with KZG. this indeed requires a trusted setup; however, the resulting Params does not contain the secrets used in the setup. instead, it contains only publicly known commitments to them. to find out more about the KZG trusted setup: https://vitalik.ca/general/2022/03/14/trustedsetup.html
A: Yeah, it looks like I was mislead by the KZG params description from pse fork sources and decided that the same goes for IPA as well. Thank you guys a lot for the explanation, that is really helpful. So if I want to use KZG scheme (which allows params, vk and pk serialization), I have to use trusted setup, and if I wish to avoid trusted setup I have to use IPA scheme, which currently doesn’t support serialization (as far as I saw in GitHub issues)? Maybe there is a way to have both trustless setup and the ability to share keys between different machines, that you are aware of?
zcash/halo2 will eventually support serialization, it just requires a bunch of refactoring work first we haven’t had time for But in the meantime, you can share keys between different machines, by running the same keygen on each of the machines. The keys aren’t “random”, they are deterministic This is precisely what we do currently with zcash/halo2 in its use in Zcash. Every machine has the code for the circuit, so they just run keygen once on startup and then keep the keys in memory.
So if I run i.e. let params = Params::new(4); let vk = keygen_vk(params, &empty_circuit); let pk = keygen_pk(params, vk, &empty_circuit); on 2 different machines (prover and verifier) with the same circuit code, the proof generated by prover will be verifiable by the verifier? Or does it require some more tinkering with keygen parameters? Sorry if my questions may seem pretty basic, I am still new to halo2 and mostly think based on experience with trusted setup SNARKs
As long as the inputs to the keygen functions are the same, the outputs will be as well. So yes, you need to use the same k value for Params, the same Circuit type, for both keygen_vk and keygen_pk, and the same empty_circuit instantiation (using Value::unknown() for all witnesses, but anything else that is not a Value witness needs to be the same, in order for the circuits to have the same structure).
layout / Layouter
Q: what is the point of the layouter having different namespaces? does it actually mean anything/separate anything or is it just for debugging
A: It’s purely for debugging. The namespaces are implemented via closures specifically so that in normal prover or verifier usage, they have zero cost (as the closures are never evaluated).
Q: I am not familiar with the rules for circuit layout. , I am unsure about the rules for arranging the rows of the circuit. Can the rows be laid out arbitrarily, or are there specific guidelines to follow ?
A: one important rule is that: cells queried in a custom gate MUST be assigned in the same Region. this is because the Layouter can move Regions around for optimal packing; so we cannot assume that offsets between different Regions will be preserved.
for example:
- a mul constraint that queries the out cell at Rotation::next: https://github.com/zcash/halo2/blob/main/halo2_proofs/examples/simple-example.rs#L89-L117
#![allow(unused)] fn main() { // Define our multiplication gate! meta.create_gate("mul", |meta| { // // | a0 | a1 | s_mul | // |-----|-----|-------| // | lhs | rhs | s_mul | // | out | | | // let lhs = meta.query_advice(advice[0], Rotation::cur()); let rhs = meta.query_advice(advice[1], Rotation::cur()); let out = meta.query_advice(advice[0], Rotation::next()); let s_mul = meta.query_selector(s_mul); vec![s_mul * (lhs * rhs - out)] }
- this out cell is assigned at offset 1, in the same region as the lhs, rhs cells at offset 0: https://github.com/zcash/halo2/blob/main/halo2_proofs/examples/simple-example.rs#L212-L216
#![allow(unused)] fn main() { fn mul(){ // Finally, we do the assignment to the output, returning a // variable to be used in another part of the circuit. region .assign_advice(|| "lhs * rhs", config.advice[0], 1, || value) .map(Number) } }
Runtime circuit configuration
https://docs.rs/halo2_proofs/0.2.0/halo2_proofs/plonk/trait.Circuit.html#tymethod.configure
This method does not have a &self parameter, so configuration must be independent of the concrete value of the type I implement Circuit for. Does it mean that the number of columns that I allocate for my Circuit must be constant? I.e. I can’t have a: MyCircuit and b: MyCircuit use different numbers of advice columns? Is there a way to allocate different number of advice columns (determined at runtime)? Or is it not allowed by design?
A: Indeed, currently the number of columns is fixed. This is for various reasons including simplicity of the original implementation, but it is a limitation we want to remove: https://github.com/zcash/halo2/issues/195
Allowing circuits to be fully defined at runtime would also enable us to support IRs (and thus compile circuits from other languages): https://github.com/zcash/halo2/issues/550
without_witnesses()
What is the purpose of without_witnesses method here? Is it to strip the Circuit of any prover-private information, so it can be safely sent/published somewhere? (It wasn’t clear for me from the comment, because it answers the question of how and not the question of what.)
- https://github.com/zcash/halo2/blob/642924d614305d882cc122739c59144109f4bd3f/halo2_proofs/src/plonk/circuit.rs#L475
A:
circuit.without_witnesses() has to maintain the “shape” of circuit, that is, the structural parameters that determine the set of columns, the placement of regions and gates etc.
https://github.com/zcash/halo2/issues/613
This is primarily because the layouter might need multiple passes, some of which do not compute witnesses. Usually, it’s that it would be unnecessary and inefficient to compute them on every pass, not that it would be incorrect or insecure.
synthesize()
Q:
Is Circuit::synthesize() context aware? Specifically, does it know if it’s the process of proving/verifying or key generation?
If so, is this accessible from the function?
A:
no, but FloorPlanner::synthesize() may be able to see the CS: Assignment bound it’s using:
- in keygen, this ignores advice values: https://github.com/zcash/halo2/blob/main/halo2_proofs/src/plonk/keygen.rs#L107
- in prover, this only cares about advice values: https://github.com/zcash/halo2/blob/main/halo2_proofs/src/plonk/prover.rs#L191-L215
copy_advice()
value.0.copy_advice(|| format!(“output[{}]”, i), &mut region, config.advice[2], i)?;
does this line copies the value into the 3rd advice cloumn ith row?
yes! (note: it copies to offset i in the region, which may have a different absolute row after the floorplanner passes.)
did you mean the values to be inserted may shift?
yes, even though the value is assigned at offset i in the region, the region itself may be moved elsewhere in the circuit.
We will partition a circuit into regions, where each region contains a disjoint subset of cells, and relative references only ever point within a region. Part of the responsibility of a chip implementation is to ensure that gates that make offset references are laid out in the correct positions in a region.
Given the set of regions and their shapes, we will use a separate floor planner to decide where (i.e. at what starting row) each region is placed. There is a default floor planner that implements a very general algorithm, but you can write your own floor planner if you need to.
- (from https://zcash.github.io/halo2/concepts/chips.html#chips)
we definitely need better documentation. if you have any questions that you would like the book to address, please do open an issue.
64 bit field elements / Value<F>
I need to use 64 bit field elements to call a function in a custom gate. I’m currently winging it by using “Value<F>,” is there a better way to represent a u64 in a field?
YT: to range-constrain the field element to 64 bits, you may consider breaking it into (say) bytes and looking these up in a precomputed table of values 0..=255.
something like this is done in the ECC gadget: https://github.com/zcash/halo2/blob/main/halo2_gadgets/src/ecc/chip/mul_fixed/short.rs#L79-L106
Daira:
As well as that, consider using AssignedCell<u64, F> to keep track of the type in the Rust code (note that this doesn’t by itself enforce the range constraint): https://github.com/zcash/halo2/blob/main/halo2_proofs/src/circuit.rs#L95-L164
I see, so , in
#![allow(unused)] fn main() { pub fn value(&self) -> Value<&V> { self.value.as_ref() } }
Is value returning a reference to a 64 bit max value or just the type?
YT:
value() returns a Value<&u64> which is a wrapper around an Option<&u64>.
however, this u64 type is only enforced by the Rust type system, and NOT by the circuit constraints. to range-constrain it in the circuit, you can use e.g. a lookup table.
circuit layout
I am attempting to optimise the simple example from the halo2 examples (c = a**2 * b**2).
I have removed the fixed column for loading constant and instead loaded it into advice column. Also combined the two advice columns into one. I have tried the same and seems to work (verification success and failure expectation).
The circuit layout previously was using: 9 rows x 5 columns = 45 cells and after doing the above it is using: 12 rows x 3 columns = 36 cells.
My questions:
Since the cells used appear to be less, does this optimisation make sense? (even though a constant is assigned in advice instead of fixed column)
I also see additional detail called “10 usable columns” and “26 usable columns”, what does it mean and does it contribute to the prover cost?
Below is circuit layout before and after

YT: (nice diagrams!)
- assigning the
constantto an advice column changes the circuit’s intended behaviour. we no longer have the guarantee that the finalc = constant * absqis a multiple of the desiredconstant, since the prover could have witnessed any arbitrary factor in its place. - for your provided
k = 4, you getn = 2^4 = 16rows, the last few of which are “poisoned” (unusable). to see how and why these rows are poisoned: https://github.com/zcash/halo2/blob/main/halo2_proofs/src/plonk/circuit.rs#L1433-L1460 - the prover cost is largely dominated by the size of
n. roughly speaking, there is a tradeoff between no. of rows and no. of columns: for the same area, a shorter/wider circuit has a faster prover/larger proof; and a longer/narrower circuit would have a slower prover/smaller proof.
constant in halo2
Q: Hi! I’am a little confused about constant in halo2? It seems that you don’t need to copy from a fixed column to constraint a cell to a constant in halo2? see my issue for more details: https://github.com/zcash/halo2/issues/766. Looking for your reply. Thanks!
A: the constant value will be assigned to a cell within one of the fixed columns configured via ConstraintSystem::enable_constant.
so behind the scenes, the assign_advice_from_constant API still creates a copy constraint between a fixed cell and an advice cell.
Q: Thank you for your reply.But i still confused because ROUND_CONSTANTS in the code is not a fixed column.It’s just a [u32; 64]. See: https://github.com/zcash/halo2/blob/2bdb369393c11dfd093d68f9253e8f12e9e6281a/halo2_gadgets/src/sha256/table16.rs#L26-L36
My question could turn into: why CompressionConfig in sha256 gadgets doesn’t need a Column<Fixed> ? 😫 https://github.com/zcash/halo2/blob/2bdb369393c11dfd093d68f9253e8f12e9e6281a/halo2_gadgets/src/sha256/table16/compression.rs#L433-L454
YT: i think you found a bug in the experimental sha256 gadget! ROUND_CONSTANTS should definitely be copied from a fixed column.
e.g. this is how Poseidon initialises the rate and capacity elements: https://github.com/zcash/halo2/blob/main/halo2_gadgets/src/poseidon/pow5.rs#L291
a pull request fixing this would be greatly appreciated!
gas cost/onchain Verifier/solidity
hi, what’s the actual relation between the halo2(kzg) circuits’ scale and the zkp verification gas cost? I use the snark-verifier: https://github.com/privacy-scaling-explorations/snark-verifier to generate the solidity verifier, it seems to be more gas consumption as my circuit scale gets lager
YT: i’m not familiar with the snark-verifier, but i would guess that costs relate to this CostEstimation: https://github.com/privacy-scaling-explorations/snark-verifier/blob/main/snark-verifier/src/verifier/plonk.rs#L171-L188
CPerezz: In recursion verification circuits for KZG, the more Advice columns and the larger they are, the more you pay at proving time.
As for the solidity verifier, it should scale only with respect to the amount of columns used.
Han: yeah the gas cost would scale mostly with the amount of columns used, see this for more accurate estimation https://github.com/privacy-scaling-explorations/snark-verifier/blob/main/snark-verifier/src/loader/evm/util.rs#L97.
GPU
Q: Does Halo2 real prover use GPU? (for e.g. in M1/M2 chip series laptops)
A: No. Although you can use pasta-msm crate to derive ECC ops to GPU. (It can require to adapt things a bit)
zkml related
Q:
I have a very general question about the Circuit trait: as we have to define gates & columns within fn configure(meta: &mut ConstraintSystem<F>) -> Self::Config;, all gate configurations have to be known at compile time, unless I’m overlooking something! I don’t see a good reason for this, at key generation time should be enough? In my case, I’m implementing a prover for a machine learning model, and some gate constraints depend on the model structure, which is not fixed at compile time. See also my issue here: https://github.com/zcash/halo2/issues/771
A: i would recommend looking at how ezkl does it! will try to find a more specific example later: https://github.com/zkonduit/ezkl
Reply : Thanks, that was good advice! It turns out that halo2 has a circuit-params feature, which does exactly what I need here. I’ll put more details in the linked issue for future reference and close it. Looks like it only works in the PSE fork though, was merged 3 weeks ago: https://github.com/privacy-scaling-explorations/halo2/pull/168
trusted setups
Hi guys, do you know where to find trusted setups for a kzg-based ceremony?
https://github.com/iden3/snarkjs#7-prepare-phase-2
Q: What is the correct way to use that?
#![allow(unused)] fn main() { let f = File::open("src/powers_of_tau/powersOfTau28_hez_final_18.ptau") .expect("couldn't load params"); let mut reader = BufReader::new(f); let params = ParamsKZG::<Bn256>::read(&mut reader).expect("Failed to read params"); }
When running this I get the error Failed to read params: Custom { kind: InvalidData, error: “input number is not less than field modulus” }
CPerezz: Are you sure that the endianness and format are the same for the Bn256 struct and the ptau file elements?
No, I’m not. Mine was more of a naive effort 🥲
I think this is probably the issue. You should just generate a trusted setup with Halo2 and figure out the serialization differences later. Once you need to use the actual ptau
For using existing KZG trusted setup, we have already converted perpetual-power-of-tau and hermez into pse/halo2 format here (https://github.com/han0110/halo2-kzg-srs), so we can download and use directly, or in the same repo it also has a script for us to do the conversion manually.
circuit k
Q: Whats the max number of rows in PSE’s Halo 2? Ive heard k=28 (2^28) through the grapevine, but I cant find anything anywhere that says this.
A: I think @CPerezz @Han could point you to this; iirc, the trusted setup was 2^28 since that’s the two-adicity of the BN254 scalar field, but i think they limited their circuits to 2^25 to allow for higher-degree constraints.
I think is the max you can use with Halo2 and BN. We have 1 spare root JIC. You will need 100’s of TB of RAM to compile a 2^28 circuit anyways. And yes, we capped the zkevm circuits to 2^25 max. And ideally would be nice to lower that
Q:
Can we auto estimate minimum value of k given a circuit object? or is the only way to manually try to find it? (edited)
A: to get the minimum no. of rows required at configure time, you could do:
#![allow(unused)] fn main() { let mut cs = ConstraintSystem::<Fp>::default(); MyCircuit::configure(&mut cs); println!("minimum rows: {}", cs.minimum_rows()); }
- for synthesis it’s a little trickier.
- when making a real proof, we would likely already be working with some hard-coded k in the params (e.g. random generators for IPA, powers of tau for KZG).
- but for dev purposes, i think we could write a FloorPlanner that just returns the no. of rows used.
thanks, this is very helpful for setting k for dev purposes cs.minimum_rows().ilog2() + 1
for synthesis it’s a little trickier.
I just realised it doesn’t include synthesis. Is it still possible to estimate a value of k inclusive of synthesis? E.g. let the synthesis run without a row bound and see how much it consumes, so it does not require inputting value of k in MockProver and for other utilities e.g. generating diagrams.
negative/overflow
Q: Is there any way to express negative values in Halo2 witness cells? I assume the answer is no since there are no integers in Fp. Checking for confirmation
Daira: The most efficient encoding of a negative value -x is usually as p-x. Obviously you will have to consider the possibility of overflows.
Can you please explain what would be a case in which an overflow may cause odd behaviours?
suppose for example that the circuit is checking a nullifier for a Zcash-like cryptocurrency. If more than one possible value is accepted for the nullifier, then there is a double-spend bug. Depending on other details of the circuit, it’s likely that an overflow would allow that.
For example, if the range check on α described at https://zcash.github.io/halo2/design/gadgets/ecc/fixed-base-scalar-mul.html#base-field-element were not performed, then you could witness two possible values of α (by varying ψ) that give the same nullifier. This could also occur if there were any mistake in the range check due to overflow. Fixed-base scalar multiplication - The halo2 Book
(As it happens, the correctness of the range check actually relies on underflow in the case where it constrains 0 ≤ α_0+ 2^130 − t_p < 2^130. So overflow or underflow is not always harmful as long as it’s accounted for.)
F_r / F_q …
Hi I saw you’re also in the PSE discord and hence I think asking you would be better. If I’m trying to modify the sha256 gadget for halo2wrong how can I know where should I use Fq and where to use Fr? More generally how should the fields change?
CPerezz — 02/27/2023 5:12 PM You should use the Scalar field always. If you’te using halo2wrong with Bn you should use Fr IIRC
What you want is basically to port the gadget to halo2wrong API/chip. Is that right?
wait to be organized…
Q
Hi, how is it possible to constrain equality between an instance cell and an advice cell without first using assign_advice_from_instance() followed by constrain_equal ?
Because calling assign_advice_from_instance() adds 25% proving time.
I gather since this issue is still open, it is not possible yet https://github.com/zcash/halo2/pull/625
A assign_advice_from_instance() does precisely what you’d otherwise do manually (if we exposed APIs to directly constrain instance cells, which we don’t currently for UX reasons): it assigns the given advice cell with the same value as the instance cell holds, and then calls (effectively) constrain_equal. So the only difference between that and what you’re doing is that you have an additional constrain_equal call, and I don’t see how that could cause the prover to be 25% slower.
Q I struggle to find a place where parsing of operations for an Expression is being handled. It’s pretty clear how both evaluation and degree computation rules are defined, but isn’t there some structure like Abstract Syntax Tree, …? A Expression is defined here: https://github.com/zcash/halo2/blob/main/halo2_proofs/src/plonk/circuit.rs#L488-L509
there’s no parsing because you directly create instances of Expression using its operators and constructors for example, the operators are defined here: https://github.com/zcash/halo2/blob/main/halo2_proofs/src/plonk/circuit.rs#L723-L765
so Expression is the Abstract Syntax Tree type.
That I was able to understand, but the expression is coming from create gate function if I’m not wrong?
Normally, in the configure method of a chip, you would call query_* methods on the passed-in ConstraintSystem (which return Expressions), and then combine them with +, -, and *. Does that answer your question?
ahh yes I see…, operations are defined for Expression type so compiler will actually know to create AST from equation, it was obvious, not sure why i got confused with it
Q This might be a dumb Q:
- I’ve been looking into the various ways witness generation works in ZK libs. In Circom for example, they do some crazy codegen from the Circom template code, and generate a .dat file + some Cpp which automagically generate the witness given some inputs. How does this work in Halo2?
A A1: There’s no magic; you write all of the code to generate witnesses in Rust. The API encourages you to do this in the same place as enabling the corresponding constraints. (That was a lesson we learned from libsnark where witness generation and constraint enforcement were separated; it was very error-prone.)
A2: The way it works in halo2_proofs is the same way it worked in bellman (drawing from the same learnings @Daira Emma (ze/hir) — ECC mentioned above): during synthesis, you write Rust code that uses AssignedCell, which wraps a pointer to a cell within the circuit and its assigned (if known) Value. You operate on the cells either directly or via gadgets, and every time a new cell is assigned, a closure is provided that evaluates to the value of that new cell. The closure is only evaluated when we need it (so for cells in advice columns, we only evaluate the closure during proving). The core idea is that the only spot where circuit synthesis and witness computation can significantly deviate is either inside that closure, or inside Value::map, which are both generally localised within the circuit synthesis code, and thus easier to compare against for bug finding.
Q How does one deal with variable length public inputs? I have a secp256k1 public key as a public input, but it can either be in uncompressed form (65 bytes) or compressed form (33 bytes). It is laid out in 65 or 33 rows of an instance column.
I want to write a gadget that verifies that an ECDSA signature corresponding to this key is correct. I plan to witness the public key in some advice columns (using halo2wrong techniques) and check that the bytes of this witnessed public key match the bytes in the instance column. Do I write constraints for both cases (65 and 33) and check that one of them is satisfied?
A if i’m understanding the formats correctly:
- uncompressed: 0x04 | x | y
- compressed: parity | x, where parity is either 0x02 or 0x03
we could do something like :
- if the key is in the compressed form, pad it with 32 0 bytes, so that we always have a 65-byte public input;
- use the first byte as a isCompressed flag;
- copy in all 65 bytes of the key to advice cells;
- if isCompressed = 0x04 (uncompressed key), check that each witnessed byte equals each public input byte
- if isCompressed = 0x02 | 0x03 (compressed key), check equality of the x-coordinate bytes, and check that the last 32 bytes are all-zero
i think we would also need an extra parity consistency check in the compressed case. (i’m assuming that, in either case, we’ll need to witness the full y-coordinate in the circuit.)
Thanks for taking the time to explain this approach! This makes sense.
In addition, you need to check that the curve equation holds for the witnessed x and y coordinates
Is this to avoid an attack where a malicious y-coordinate could be used to verify a forged ECDSA signature?
It’s to avoid being able to forge proofs. If you don’t verify the curve equation then later constraints that assume the coordinates are valid will potentially be unsound. Also, for compressed encoding you have to implement the curve equation anyway to recover the y coordinate, so it’s no less expensive. In fact, what you’d do is witness the x and y coordinates with a curve check (like you’d do to witness any arbitrary curve point), witness the encoding, and then check consistency between the two (so checking the coordinates match for uncompressed, checking the sign bit of y for compressed).
Q Question about lookup tables: It seems that halo2 enforces that lookup tables have the same length. What do I do if I want them to have different lengths? A A1: Do you mean the fact that the tables themselves must have the same number of rows as the circuit? You just fill each table up with however many rows it needs, and the backend will fill the rest of the rows with an appropriate default value. Lookup tables need to live in separate fixed columns, so the fact that two tables have different “real” sizes doesn’t matter as they won’t interact (and the backend pads them to the same number of rows).
A2: to have two logically different tables “share” the same column, we could introduce an extra tag column that serves to index the tables. the inputs to the lookup argument would now also have to include an input_tag to specify which logical table it is using.
A3: I think we should handle this via the new dynamic table API (since that introduces the tag column, and does not actually require that the table uses only advice columns)
Q
Hey everyone, I’m trying to get the max of two Values (ex: two Value<Fp> variables). Ideally I’d like to just compare the underlying field elements but it doesnt look like those field elements can be extracted(https://github.com/zcash/halo2/blob/main/halo2_proofs/src/circuit/value.rs#L11). Is there a quick workaround for this?
#![allow(unused)] fn main() { /// This behaves like `Option<V>` but differs in two key ways: /// - It does not expose the enum cases, or provide an `Option::unwrap` equivalent. This /// helps to ensure that unwitnessed values correctly propagate. /// - It provides pass-through implementations of common traits such as `Add` and `Mul`, /// for improved usability. #[derive(Clone, Copy, Debug)] pub struct Value<V> { inner: Option<V>, } }
A
Hey everyone, I’m trying to get the max of two Values (ex: two Value<Fp> variables). Ideally I’d like to just compare the underlying field elements but it doesnt look like those field elements can be extracted(https://github.com/zcash/halo2/blob/main/halo2_proofs/src/circuit/value.rs#L11). Is there a quick workaround for this?
Q-1 Can you do a.zip(b).map(|(a, b)| f(a, b))?
A-2 i dont think so (unless the a, b are Fp vars) . so i think the issue is that Value doesnt implement the Ord trait which is what I want to be able to do comparisons on Values.
Q-2 Sorry, that was a bit confusing, this: a.zip(b).map(|(x, y)| f(x, y)), If a, b are Value<Fp>, I believe that inside the map the x, y are &Fp.
A-3 ah my bad, yea that’ll work. thanks !
A-4 Yep, that’s the intended way to implement operations that Value doesn’t expose
Q
SUN-YI: On a related note, is there an intended way to check whether two Values contain the same inner Option? (I’d like to use this to test witness generation code programmatically, so I want to get a bool.)
A Use Value::assert_if_known or Value::error_if_known_and. You’d map the two values into one containing a tuple, then use the above methods.
Q
SUN yi:
I am in a situation where I’d like to read the inner value in a Value<F> for witness generation. Is this possible in any way in the 0.2.0 API?
The specific operation I want to do is:
- I have a x:
Vec<AssignedCell<F, F>>and a separate idx:AssignedCell<F, F>and I know that 0 <= idx.inner < x.len(). - I’d like to find the array y so that y.len() = x.len() and y[i] == x[i] if i < idx.inner and y[i] is a newly assigned fixed 0 cell if i >= idx.inner. Is there some way to do this?
A
lyt: where is i coming from?
i think we’ll probably need an upper bound on how large i can be, i.e. how long the y vector can be
str4d - ECC: In this scenario, the length of x is fixed in the circuit structure, as it is effectively Vec<Value<F>>.
So what you want to do here is something like:
#![allow(unused)] fn main() { let mut y = vec![]; for (i, x_i) in x.iter().enumerate() { let y_i_val = x_i.value() .zip(idx.value()) .map(|(x_i, idx)| { if i < idx { x_i } else { F::zero() } }); let y_i = region.assign_advice( ..., || y_i_val, ); y.push(y_i); // Also need to enable some // constraint that enforces the // relationship on each cell. // The constraint would be where // the fixed 0 gets constrained // once i >= idx. } }
SY: My understanding is this assigns a new cell for each cell in y. Is it possible to have the first idx cells in y simply be clones of the AssignedCells in x, thereby assigning fewer cells? (In the 0.1.0 API, I believe this was achievable by handling the None and Some(idx.inner) values for idx separately.)
Yes, but only if idx is baked into the circuit and not chosen by the prover.
If idx is inherently a Value<usize> (i.e. Value::unknown() during keygen) then what you describe doing is a circuit bug.
But if it’s a usize (i.e. known at keygen time) then yes, this can be done
I see — is the idea that the location of the cells in y in the grid must be fixed at keygen time?
Sort of. It’s more that the relationship between the cells defined as y, and the places that y is constrained later, need to be fixed at keygen time (as those constraints are your circuit). That means you can’t change which cells y refers to at proving time, or you are leaving your circuit under-constrained, which is (usually) Bad.
Q hey, has there been any discussion around what determines the proof size ? A See the proof_size and marginal_proof_size methods in https://github.com/zcash/halo2/blob/main/halo2_proofs/src/dev/cost.rs
Q is there a standard library/implementation people use for range checks? A SY: We just open sourced a library of base components including range check here: https://github.com/axiom-crypto/halo2-lib/blob/main/halo2-base/src/gates/range.rs
Q How many advice columns is considered too many? Are 500 columns ok? I am trying to implement a circuit that can prove ownership of a Bitcoin UTXO. This involves activating gates in response to Bitcoin opcodes. There are about 200 such opcodes. Each opcode will require at least one column as an indicator function. If I don’t mind the large proof size (for now), is it feasible to have 500 columns in a halo2 circuit. A We previously had issues with that many columns because the Orchard circuit only used 10 so we hadn’t tested that high. But then the zkEVM people came along with a similar issue (EVM opcodes) and started exercising those dimensions, and a bunch of performance improvements have been made that should mean it works fine now.
Q Jason m: Getting stochastic failure (proof sometimes verifying, sometimes not verifiying), even with the same pk held in memory. Any guesses as to why? I will work on a minimal example, but if anyone knows of another place this has happened, we would appreciate a pointer.
A-1: I have encountered the similar issue while some logic in the synthesis iterates a HashMap. I saw in ezkl while model configuration, it also iterates over a HashMap to configure the ConstraintSystem, which might lead to constraints with different order (then verifying would fail). Could this be the issue?
Q-1 Could be! Will check it out. ……. Looks quite likely that this is the problem, once we finish confirming it we will switch that HashMap that snuck in with BTreeMap. Thank you @Han !!
Q
Hi, I’m trying to prove that a certain ASCII character X is not present in a string. What would be a more efficient way to do it?
I could put all ASCII chars (except X) in a lookup table and prove that the string contains only the chars from the lookup table
(Ideally, I could use a multiset equality check but it is still wip in halo2)
Is there any better way than the lookup table?
Thanks.
A-1 : The simplest way would be to have a constraint of the form char - NUMERIC_VALUE(‘X’) != 0, which you can do by witnessing inv = (char - NUMERIC_VALUE(‘X’))^{-1} and then constraining (char - NUMERIC_VALUE(‘X’)) * inv = 1. This requires that char is also range-constrained to ASCII (e.g. range constrain to 7 bits).
Q-1: thank you very much. Just to clarify: you think that this approach will cost less prover time than lookup tables, correct?
A-1: Probably; the two constraints here are relatively simple. But the lookup table would also be relatively small in this instance, so best way to know is to try both.
Q We are facing a rather curious issue. The MockProver works as expected and verifies the circuit execution but the real verification fails with ConstraintSystemFailure.
- Is there any known issues regarding MockProver that justifies this behaviour?
- Generally what is the right debugging approach in this scenario?
A This is likely because MockProver does not check everything. We add more comprehensive checks over time, but it’s a development and debugging tool rather than an alternative to full verification. That being said, we’d like to figure out what these edge cases are so we can track improvements to MockProver. The easiest debugging approach currently is to gradually comment out parts of your circuit until the error goes away. That and adding print statements to determine how far through synthesis you got. Overhauling the error handling has been on the backlog for a while; I’d ideally want the error you saw to already include this information.
Q Hello, does anyone have a good code example of a circuit that uses the V1 floor planner? I’m trying to switch my circuit to it, but it expects my circuit’s synthesize function to work on the default circuit (from without_witnesses), which it’s not designed to do. I’m assuming to fix this I’ll need to refactor to use the Value enum everywhere, but before I start on that I’d love to see a working example using the V1 floor planner
A
If your circuit doesn’t synthesize with the default circuit, then it very likely has bugs.
More specifically, Circuit::without_witnesses shouldn’t return Self::default(), but should instead construct a copy of self that omits witnesses (anything you currently store as Option<T> and would store as Value<T> after the refactor), but including everything else.
That is necessary because the “everything else” is necessarily affecting the structure of the circuit, and the structure of the circuit must not change between calls to synthesize. This doesn’t just affect the V1 floor planner; it affects the simple one as well, because keygen calls synthesize without any witnesses.
Q-1: Huh, I haven’t had any problems using the simplefloorplanner with my circuit; both using the mockprover and proving/verifying real proofs I’ll definitely change my circuit to reflect the ‘proper’ way of doing without_witnesses though. Although you may want to change the examples to reflect this design, since most current examples given use Self::default() for without_witnesses Thanks for the tips!
A-1: Yep, there’s an open issue for changing the examples: https://github.com/zcash/halo2/issues/613 Self::default() works fine if Self only contains witness variables, and none of the examples have structural variables in Self.
Zcash’s Orchard circuit uses the V1 floor planner: https://github.com/zcash/orchard/blob/main/src/circuit.rs#L191
Q I am trying to understand a halo2 circuit layout using the dev-graph feature. In the attached picture, the green regions seem to correspond to assigned rows of some columns. What do the other colors correspond to? I want to understand why there is a large orange region in the middle which has the same color as the unused rows.
A The orange background indicates the advice columns, and the blue background indicates the fixed columns. The line showing how many rows are used is down past the middle because of one of the fixed columns that assigns to that row, while the advice columns are barely used.
Q-1 Thanks! I am using the halo2wrong ECDSA chip. I think the tall fixed column is 18-bit range check which takes up 2^18 rows. The advice columns in the middle have only one row used. It’s rendering is so thin compared to the rest of the columns that it is invisible. The green columns have a darker shade of green in some rows. Does that correspond to cells that have been assigned? … Also, the rightmost fixed column has a darker shade of blue. Does that signify anything?
A-1 The darker blue indicates selector columns, which are a specialized subset of the fixed columns.
A-2 And yes the darker green corresponds to assigned cells. (It is actually possible to assign the same value more than once, which I think produces an even darker green; this is useful to debug overlaps when zoomed in.)
Q
How many rows are used by halo2 “system” at the bottom of the matrix? A It is “dynamic” in that it depends on your circuit structure. Put another way, you don’t pay blinding rows for functionality you aren’t using. The actual calculation is here: https://github.com/zcash/halo2/blob/ec9dcefe9103fc23c13e8195120419d4d2f232a6/halo2_proofs/src/plonk/circuit.rs#L1432-L1472
#![allow(unused)] fn main() { /// Compute the number of blinding factors necessary to perfectly blind /// each of the prover's witness polynomials. pub fn blinding_factors(&self) -> usize { // All of the prover's advice columns are evaluated at no more than let factors = *self.num_advice_queries.iter().max().unwrap_or(&1); // distinct points during gate checks. // - The permutation argument witness polynomials are evaluated at most 3 times. // - Each lookup argument has independent witness polynomials, and they are // evaluated at most 2 times. let factors = std::cmp::max(3, factors); ... }
Thank you, this is the calculation I was looking for. So the max assignable rows should be 2^k - meta.minimum_rows(), where the call to minimum_rows happens at the end of layout (because it increases as queries occur)?
Yeah. This is also why the “not enough rows” error doesn’t suggest a value of k that will fix the problem, because it was always suggesting current_k + 1 and then immediately encountering the error again as we progress further through Circuit::synthesize.
Q Is the protocol described here https://zcash.github.io/halo2/design/protocol.html same as the actual protocol that has been implemented in the zcash’s halo2 repo? A Yes. That page matches what the halo2_proofs crate currently implements, and provides a security argument. If in future backwards-incompatible changes are made to what halo2_proofs implements (which are likely necessary for implementing recursion/recursive), that page will also be updated.
Q how difficult would it be to swap the Pasta curves in the IPA of zcash/halo2 with Secp256k1 curves, as implemented here: https://github.com/privacy-scaling-explorations/halo2curves/tree/main/src/secp256k1 I know FFT would be slower but for example, private secp256k1 ECDSA signature verification inside the circuit would be very few constraints due to no wrong field arithmetic? A Definitely doable; secp256k1 has the necessary curve cycle. The main issue currently is that there are extension traits in pasta_curves that halo2_proofs depends on, so you’d need to maintain a dependency on pasta_curves for now (though we are working on moving these pieces upstream into ff and group). There might also be a few spots inside zcash/halo2 where we explicitly depend on pasta_curves curve types, though I think those are in halo2_gadgets (just places we didn’t have time to generalise while implementing Orchard), and halo2_proofs is fully generic?
Q-2: Appreciate the speedy reply! It looks like in the README they’ve implemented the halo2 traits for FieldExt and CurveExt for these curves as well, so does that cover the first part of what you are saying?
Yeah, that should be sufficient
I got it done! yay! (I got secp256k1 working for the IPA in a very simple proof. still need to benchmark the full ECDSA signature verification code)
Q Referring to this doc https://zcash.github.io/halo2/design/protocol.html, Is this correct to consider that lookup gates are included in the description of the function g(X, …) ?
Also, what are the polynomials s_i(X) that are being constructed in step 10 ?
A Conceptually yes. The actual constraints depend on two challenges β and γ that must be sampled after committing to the other columns — i.e. other than (A’, S’, Z computed in the lookup argument and the product columns in the permutation argument) I don’t see the sampling of those challenges in the protocol steps; maybe they were merged with some of the x_i or maybe those steps are just missing (you’d have to look at the code to check, or @seanzcash would know). In any case we use β and γ for both the lookup argument and the permutation argument
Q Can you give an intuition on why multiplying (1 - q_last(X) - q_blind(X)) polynomial helps in imparting zk to both lookup and permutation arguments? I noticed that this is different than how it was done in the Plonk paper. A It’s not that it helps impart zk to those arguments, but that it is necessary to prevent those arguments from being broken by the way we do zk in Halo 2. We require some number of “blinding rows” in the table, which are assigned random values in the advice polynomials. These random values cannot participate in the lookup and permutation arguments because their contents are by definition random and thus don’t follow e.g. the sorting / arranging requirements of the A’ and S’ polynomials in the lookup argument. So we use the above constraint factor to ensure that the blinding rows are unconstrained by the lookup and permutation arguments.
A-2: if zk were not needed, then the description of the protocol before “Zero-knowledge adjustment” would work. But that relies on the references to next and previous rows “wrapping around” at the last and first row respectively. If there are blinding rows that have random contents, then the constraints would not be satisfied at those rows
Q If I want to prove that an advice column is a permutation of a fixed column, what API call can I make inside meta.create_gate to generate the permutation proof? A this is a multiset equality check and there is currently no API for it: https://github.com/zcash/halo2/pull/669
you could use meta.lookup to check that every entry in the advice column appears somewhere in the fixed column; but this isn’t the same as checking that it’s a complete permutation of the fixed column.
Q Hi I am currently working on a ZK SNARK system with verifier within smart contract on an ethereum-based blockchain. The system currently works with GM17 protocol and verifier is mostly generated by a tool which creates Solidity file for it.
I am not sure if that is possible to bring Halo2 verifier to EVM since compiling Rust code is not an option I am aware of (there is EWASM but as far as I know it’s under development and not coming any time soon) and writing verifier from scratch in Solidity seems like a lot of challenge. So I would like to know if anyone is aware of any way to bring Halo2 verifier to EVM or heard of any work in this direction. Any help or advice would be greatly appreciated
A I have not dug very deep yet but I asked this question in a different discord and was pointed to Scroll’s work: https://github.com/scroll-tech/halo2-snark-aggregator/tree/main/halo2-snark-aggregator-solidity I am not experienced enough with it to tell you whether or not this is a usable SDK for putting Halo 2 proofs on-chain, or if you would have to use it as an example and copy a bunch of boilerplate code to do so
There is also generic PLONK verifier from PSE team’s work(https://github.com/privacy-scaling-explorations/plonk-verifier) which generates Yul verifier internally. It can work as PSE’s Halo2 verifier itself. (Not sure whether it works for ZCash halo2)
Q hi, is there any example of a simple circuit where an instance column is used in create_gate. So, no constrain_instance is used. All the examples that I see constrain a cell to instance column cell.
For example, a circuit where the element wise product of two advice columns (a,b) is equal to the instance column (c). I created a gate specifying a*b-c, and assigned a,b through layouter.assign_region, but looks like I am missing something as the MockProver is failing.
Anything more that i need to do?
A Instance columns can’t be easily used directly in gates, because gates are enabled relative to regions, and regions can be arbitrarily reordered, while instance column contents cannot. If I recall correctly, it still might be possible to set this up, but you’d need to be using a floor planner that does not do any packing, which is less efficient.
I see. since i am just developing a toy circuit, I used SimpleFloorPlanner. After I posted the question, I updated the gate to be q_sel*(a*b-c), and it worked. So looks like a selected is always necessary to pass?
The mock prover might be making assumptions about gates having selectors? But it shouldn’t, since that isn’t strictly required.
Q is there any documentation using a real prover/verifier for a halo2 circuit? A there’s a PR for this: https://github.com/zcash/halo2/pull/670/files#diff-93ad4e38438d6dd3ae11bc620ae22751d0d80f38a3e44695944de044078e568eR340 Also there is this test https://github.com/zcash/halo2/blob/main/halo2_proofs/tests/plonk_api.rs
Q Is it possible to use halo2 with gpu, when creating a proof? A Not yet, but there is work being done towards this that will hopefully make its way into halo2_proofs in the near future.
Q Hello! Noob question, wondering what the “Z” and “U” values for a fixed base are. (https://github.com/zcash/halo2/blob/677866d65362c0de7a00120c515a9583b2da2128/halo2_gadgets/src/ecc/chip/constants.rs#L150-L156) https://github.com/zcash/halo2/blob/677866d65362c0de7a00120c515a9583b2da2128/halo2_gadgets/src/ecc/chip/constants.rs#L108-L117 is find_zs_and_us so I think I can just use it without knowing why it works
A So for a table of w points we should be able to represent the choices of y-coordinates in w bits. Alternatively, if we have some piece of information (represented by a single field element z for each table) that “randomly” generates those bits, and provided w is not too large, then we can search for z that happens to generate the correct values for the w bits Half of all field elements are squares. So, there may (will, because the field is large) exist z such that z + y is square and z - y isn’t, for every point (x, y) in the window table. Then if the prover witnesses a square root u of z + y, and we also check the curve equation, then we know that we have the correct y (and not its negation)
Q Hello frens, Im trying to write create a WASM version of Poseidon hash. I started implementing the WASM wrapper and ran into an issue very early on. When adding halo2_gadgets and halo2_proofs as dependencies. https://github.com/ImmanuelSegol/zk-benchmarks/blob/main/halo2-wasm/Cargo.toml
I get the following error when compiling:
Anyone know why this happens ? Im abit new to rust as well so maybe im missing smtn. but shouldn’t t halo2_gadgets and halo2_proofs be includable in a wasm project without throwing an error. if i remove halo2_gadgets and halo2_proofs my wasm compiles correctly Thanks
Q
what is the reasoning behind the fact that From<u64> is only enforced by PrimeField and not by Field directly??
It’s annoying in halo2 where sometimes you would be Ok with F:Field as trait bounds and you need to add extra stuff just due to this 😦
I’m sure I’m missing something here. Could you enlight me?
A I guess there is always a well-defined embedding of Fp into F{p^k}, but it isn’t entirely obvious to me that this is what you would want for a From conversion. (Consider for example F{2^64}; should that just discard all but the low bit?)
Q:
Hey Daira! I’m not sure how this is linked to the trait itself. The main difference between Field and PrimeField is just that, that one of them is guaranteed to be Prime order and so, has extra methods avaliable. And this doesn’t really apply to From<u64>. My concern was more towards rust-API perspective as I did not think that this had something to do with theoretical background.
A:
Finite fields can be either prime or extension fields. My point is, what’s the intended semantics for From<u64> on an extension field? It isn’t obvious.
Q
Ohh I see. I don’t think the distinction applies for extension fields. I would never expect From<u64> to have anything to do with exponentiation even if working with extension fields. It’ll purely: turn into F encoding-form this u64 value. For what you were referring, I’ll always expect the need to do: let x = F::from(2u64).pow*&[64u64,0,0,0]) to express F{2^64}. (edited)
A
So, if you know that you don’t have an extension field, what stops you from using the PrimeField trait as a bound? (Genuine question.)
Q: Ohhh mainly the fact that I leave a way less fn calls avaliable open and we save compilation time. If I can restrict more the trait, it allows to call a lot less stuff and also, the compiler has less things to worry about. My question is also genuine in the sense that I don’t really purpose to change it. But it’s like having F::ONE as PrimeField instead of Field. Is such a basic thing that I’d expect to get it from the Field trait directly.
str4d - ECC:
- @CPerezz the core question is “how should a u64 integer be mapped into the field?” This question is easy to answer for prime fields: there is a 1:1 mapping as long as the field is at least 65 bits.
ff_derivesupports a minimum of 64 bits for modulus size, so in that case there may be a slight reduction, but it’s not too noticeable. For binary or extension fields the question is harder to answer, and will depend on the structure of the field. There is not an obvious mapping that is correct for every possible field.
This is also why we have Field::ZERO and Field::ONE, but only PrimeField::TWO_INV. The first two are valid for every field (because fields have both addition and multiplication, and therefore must have both additive and multiplicative identities), whereas 2^-1 is only present for fields in which 2 has an inverse (which does not include binary fields).
Others
Q
JM:
enable_equality is completely idempotent, right??
“idempotent”(幂等)这个术语通常用来描述一个具有特定性质的操作:无论进行多少次,其效果都是一样的。当我们说一个操作是“完全幂等的”(completely idempotent)时,我们是在强调这一点:不管这个操作执行一次还是多次,结果总是相同的。
A You mean the API that enables a column to be used in equality constraints? Yes, using it multiple times on the same column has no additional effect.
Q
jasonmorton:
What’s the difference between Constant (constrain_constant) and Fixed (assign_fixed)? Both use a cell for a value that is fixed at circuit creation time, and is part of the circuit definition.
Which one is most appropriate for values to be used in constraints?
I want to add (as cheaply as possible) the constraint 3x+5y=0, where x and y are witness values and 3 and 5 are fixed when the circuit is defined.
A assign_fixed should be used for values in constraints, because the constraint has to be enabled at some relative offset within the region. 因为必须在区域内的某个相对偏移处启用约束。
constrain_constant assigns a value in some unused fixed cell after all regions have been allocated; it should be used to equality-constrain single cells in the global permutation. constrain_constant 在分配所有区域后在某个未使用的固定单元中分配一个值; 它应该用于在全局排列中平等约束单个单元。
Q Thank you. Is using assign_fixed with a fixed column, and assign_advice with an advice column the same prover and verification cost then? A No; roughly speaking, advice columns are more expensive
Q: hey a question about PSE Halo2, can anyone guide me on how to extract kzg inclusion proof from a column’s polynomial commitment? I am tracking back the code from transcript.write_point() and can figure out where the commitment is calculated, but any guidance will be helpful
A: here is where the KZG opening proof is made for multiple commitments evaluated at the same point z:
- https://github.com/privacy-scaling-explorations/halo2/blob/main/halo2_proofs/src/poly/kzg/multiopen/gwc/prover.rs
Q is halo2 book is enough to read and develop the circuit? A To read it possibly. To develop it, depends on your programming experience and the languages you’re good at. As this will probably mark how fast you get up to speed with Rust basics.
Q How come there are so many duplicated traits? Curve, CurveExt Field, FieldExt Group, Group (same name! one from group, one from pasta_curves) I have to be honest, it’s a bit confusing.
A The *Ext traits are extension traits, a way of extending an existing trait with additional functionality. We wrote those while figuring out what things we needed for implementing Halo 2 that the ff and group traits didn’t yet provide. The end goal is for those extension traits to disappear:
- https://github.com/zcash/pasta_curves/issues/42
- https://github.com/zcash/pasta_curves/issues/41
Q hey! is anyone working on (or aware of anyone working on) transpiling r1cs constraints to halo2 circuit?
A Why not just change the protocol to support R1CS? That would be more efficient, no? Halo 2 is made to prove a PLONKish circuit. If you just want to support R1CS, you could drop lookups, etc.
Transpiling should be more efficient, because you can make use of multiple columns to compile more than one R1CS constraint into a single PLONKish row Depending on the sophistication of the compiler, you could also recognise repeated patterns in the R1CS constraints and compile them into custom gates, although I’m not sure whether it would be worth the effort relative to rewriting the source circuits